In this post we will have a look at the Padé approximants of and . The Maclaurin series of is:
The MacLaurin series of is:
According to the section concerning the calculation of Padé approximants using a matrix notation (see post Computing Padé approximants, we have to solve two linear systems sequentially. For we therefore have to first solve:
Injecting the coefficients calculated above in the second linear system we have:
From this system we obtain , , . Therefore:
For we have to first solve:
Injecting the coefficients calculated above in the second linear system we have:
From this system we obtain , , . Therefore:
We observe that:
These calculations suggest that, if then:
Where and are the Padé approximants of and respectively. This proposition is actually true and can be proved formally.
In the previous post we have computed the Padé approximants for the function. The approximation was not very impressive compared to the Maclaurin series of since the latter converges for all . In this post we will have a look at the Padé approximants and Maclaurin series of .
First let’s recall the graph of (see figure 1). is a function with vertical asymptotes that cannot be approximated globally by a Taylor series. The Maclaurin series of is:
Where are so-called Euler numbers:
We would like to compute the approximant of . The first step is to have a look at the corresponding Hankel determinant (which is the determinant of the Hankel matrix):
For and we have:
and the corresponding Hankel determinant for the of is:
the determinant being not equal to zero implies that we can inverse the Hankel matrix and solve the systems to compute the Padé coefficients of for (see post Computing Padé approximants). The inverse of the Hankel matrix is given by:
We have to solve this first linear system:
Solving the system above allows us to compute the coefficients (see results below). Now, according to the calculations presented in the post (see Computing Padé approximants), we have to solve the second linear system to compute the coefficients:
This implies that for :
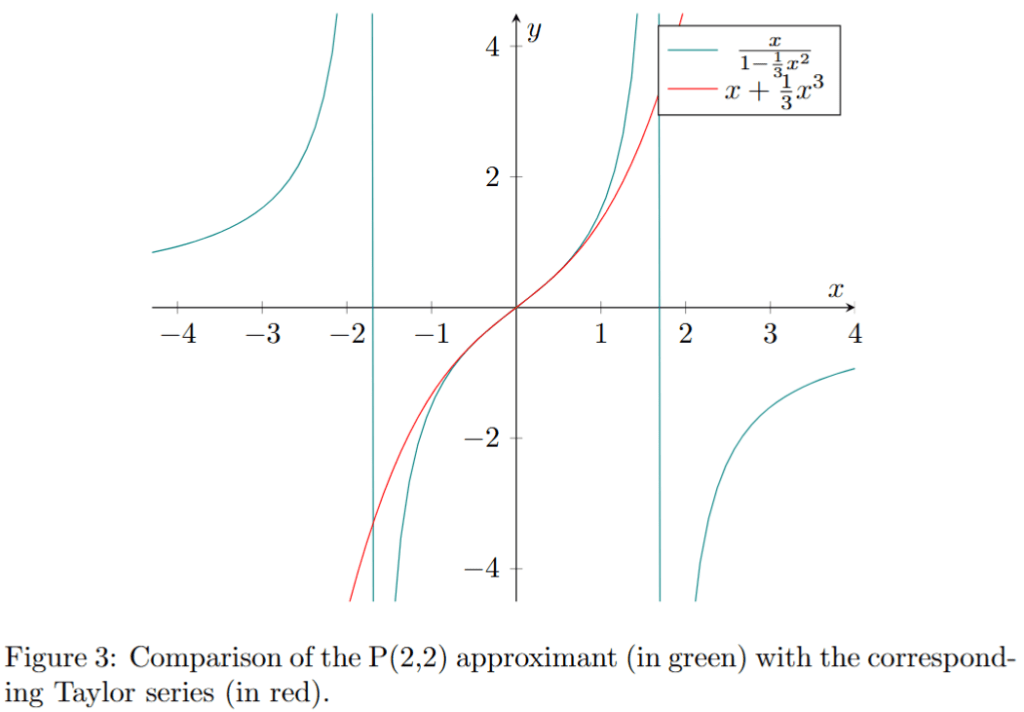
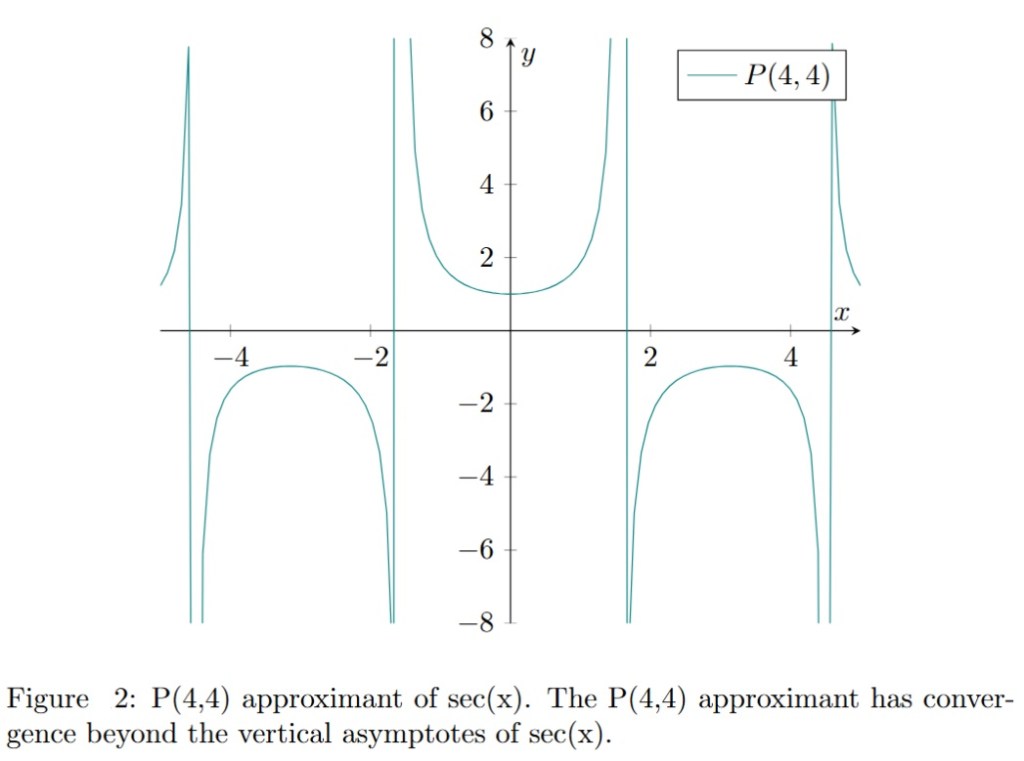
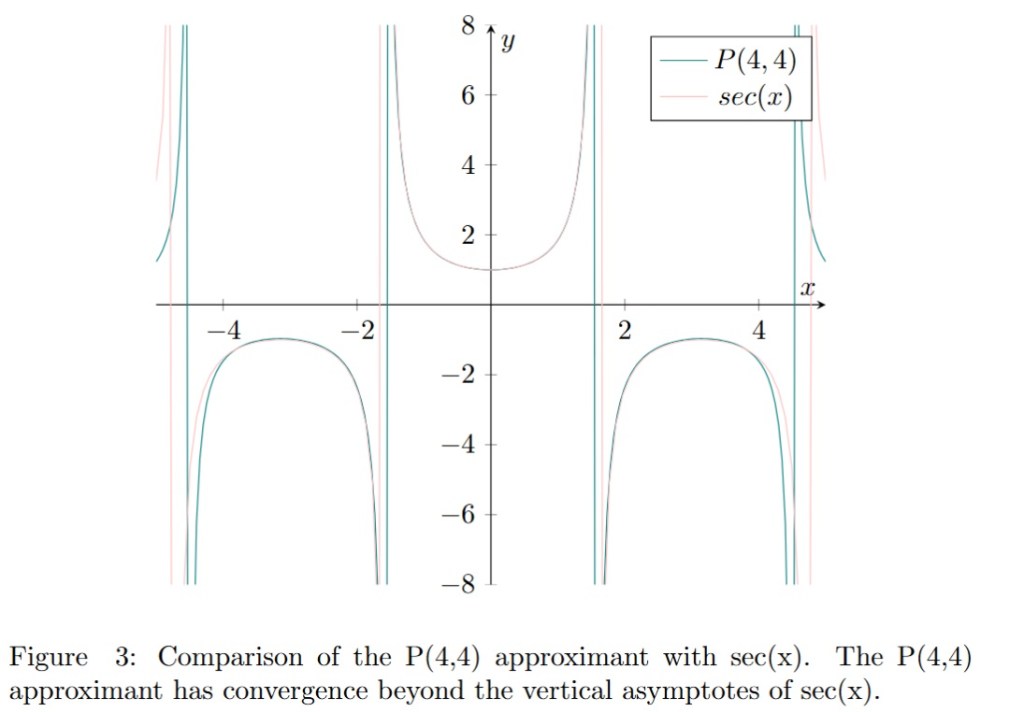
The graph of for is presented in figure 2. The graph of and its corresponding is presented in figure 3. We can see that the approximant (in green) is approximating the function beyond its vertical asymptotes (pink vertical lines) in contrast to the corresponding Taylor series presented in figure 1. Moreover the convergence of is better than the one of the Taylor series.
It is also interesting to note that the ‘information’ needed to construct the Padé approximants of the function has been extracted from the truncated Taylor series. Despite this fact, the Padé approximant provides a better approximation of the function than the series from which it is derived.
We can organize and present the Padé approximants in a table like this:
0
1
2
3
0
1
2
3
The table above shows, in order, Padé’s first approximants. This is a way to present and organize the Padé approximants. We can use the procedure presented in the previous posts to compute the Padé approximants for the exponential function . Solving systems presented in the previous posts, leads to the following table:
0
1
2
3
0
1
2
3
Setting x = 1, we obtain the following values:
0
1
2
3
0
1
—
2
3
The ‘relative error’ is defined as:
Relative errors of Padé approximants of evaluated at x = 1, using the exact value are shown in the table below:
0
1
2
3
0
1
—
2
3
The Padé approximants exhibit an alternating sign pattern in their relative errors. This indicates that the Padé approximants oscillate around the true value , approaching it from both sides. In contrast, the Taylor approximations converge monotonically from below.
In the previous posts, we have seen that in order to compute the Padé coefficients corresponding to a given geometric series we have to be invert the following matrix:
Where are the coefficients of the Taylor series. The matrix above is called a “Hankel matrix”. A ‘Hankel Matrix’ is a symmetric square matrix in which each ascending skew-diagonal from left to right is constant. For Example a Hankel matrix of size 5 can be written like this:
Let’s make some observations on the Hankel determinant :
This determinant has n colons and n rows. We can also numerate the terms of the determinant following the notation:
Where etc. This notation of the terms of the determinants implies that:
So that:
If is a even function of class , we see that odd coefficients . In this case, every second term of in the Hankel matrix is zero. If is even, we can establish that if and are odd then the Hankel determinant is zero:
The term with index of the Hankel determinant is . As stated before, this term is zero for an even function if is odd. Now, if and are odd this means that is even and is odd when is even. It follows that, in the case of an even function, the Hankel determinant is of the form:
We observe that the odd rows of this determinant are linear combinations of:
This implies that odd-numbered columns are linked and therefore the determinant is zero.
As example we will derive the of the cosine function. First we have to consider the geometric series of degrees up to of cosine:
For and ( and are both odd) the Hankel determinant is:
The corresponding Hankel determinant for calculating the coefficients of the Padé approximant of the geometric series of cosine is therefore:
This implies that we cannot calculate the approximant for the cosine function.
In conclusion, for an even function like cosine, when m and n are odd, the Hankel determinant Hn,m(f) is zero due to the linear dependence of the columns.
We have seen that Padé approximants offer a more efficient and flexible method for approximating functions than the Taylor expansion. They have been used in many areas of mathematics and physics.
We would like to find a more convenient way to calculate the Padé coefficients of any Taylor or Maclaurin series.
In the following post, we admit the existence of Padé approximants . It is generally possible to find the coefficients of the Padé approximants except in the case of degeneracy due to particular values of the coefficients of the corresponding series. We will not consider these cases in the rest of our study. Remember that we defined Padé approximants as rational functions:
If we want to solve a very hard or even impossible-to-solve-exactly problem using perturbation theory we will end up with a power series like . To convert this (potentially not converging) series to its corresponding Padé approximant we write (as described in the previous post):
From a purely algorithmic point of view and in order to calculate the Padé coefficients we drop :
Comparing each term of the geometric series on the right and the left of this equation (Uniqueness of power series coeffficients) we obtain the following set of equations:
Using for . We can split this system of equations in two parts and get rid of the x-terms. One part containing the coefficients (up to i+j = m) and the part without coefficients. The first system of equation is:
The second system of equations:
Setting without loss of generality the second system of equations becomes:
Changing the order of the coefficients gives:
We can write both systems using matrix notation:
Practically, we start calculations where . The resolution of the second system gives the values of the coefficients which are injected into the first system to obtain the coefficient (using ). So if the following determinant (called a ‘Hankel determinant’):
Is not null. i.e.:
the Padé approximant will be unique. The calculations for the Padé approximant coefficients yield a unique solution for any Taylor or Maclaurin series, provided the Hankel determinant is not null, excluding cases of degeneracy due to specific coefficient values.
We would like to represent functions using continued fractions (similarly as we did for numbers). For example, a well-known continued fraction representing is:
Continued fractions like this one typically have a bigger definition domain compared to the corresponding Taylor series. This is illustrated graphically in figure 1 and figure 2.
The continued fraction representation of a function seems a promising approach since the radius of convergence ‘seems’ at a first glance much bigger and the approximation ‘looks’ much better (i.e. converging faster) than for Taylor and Maclaurin series. We will illustrate these statements.
In order to make some progress in the construction of continued fractions corresponding to functions, we’ll start by defining the following rational functions, which will prove to have interesting properties in their own right:
Using the definitions above we present some examples using the first terms of the Maclaurin series of :
In the example above we are considering a rational function. So we consider up to 2 + 2 = 4 as the maximum degree we would like to consider for further computations. The equation above becomes:
Comparing the coefficients of both sides we obtain:
Solving the set of equations above gives:
This is clearly the first term of the continued fraction of as shown above.
as defined above are called Padé approximants. A Padé approximant is the “best” approximation of a function near a specific point by a rational function of given order. We also have convergence beyond the radius of convergence of the corresponding series.
Let’s calculate the corresponding to the first terms of the Maclaurin series of . 1 + 2 = 3 implies that we have to consider the Taylor series up to degree 3.
Keeping only degrees up to 3:
Comparing the coefficients of both sides we obtain:
We observe that (in this case):
Now we calculate the corresponding to the first terms of the Maclaurin series of . 3 + 3 = 6 implies that we have to consider the Taylor series up to degree 5:
Keeping only degrees up to 6:
This implies:
Solving the set of equations above gives:
Now consider the first terms of the continued fraction of :
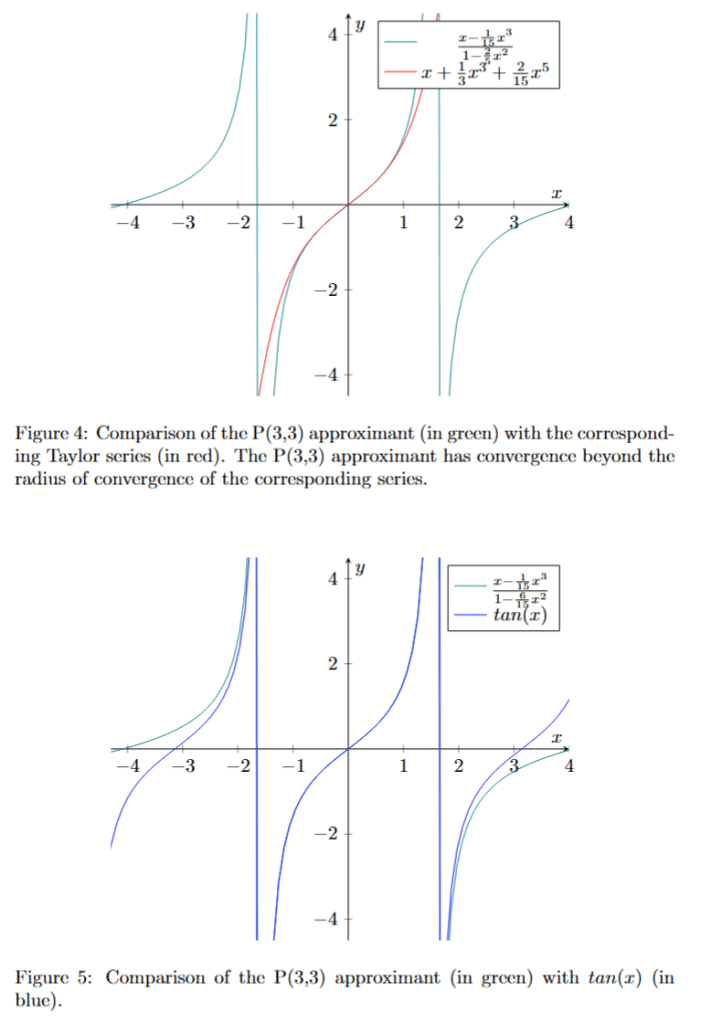
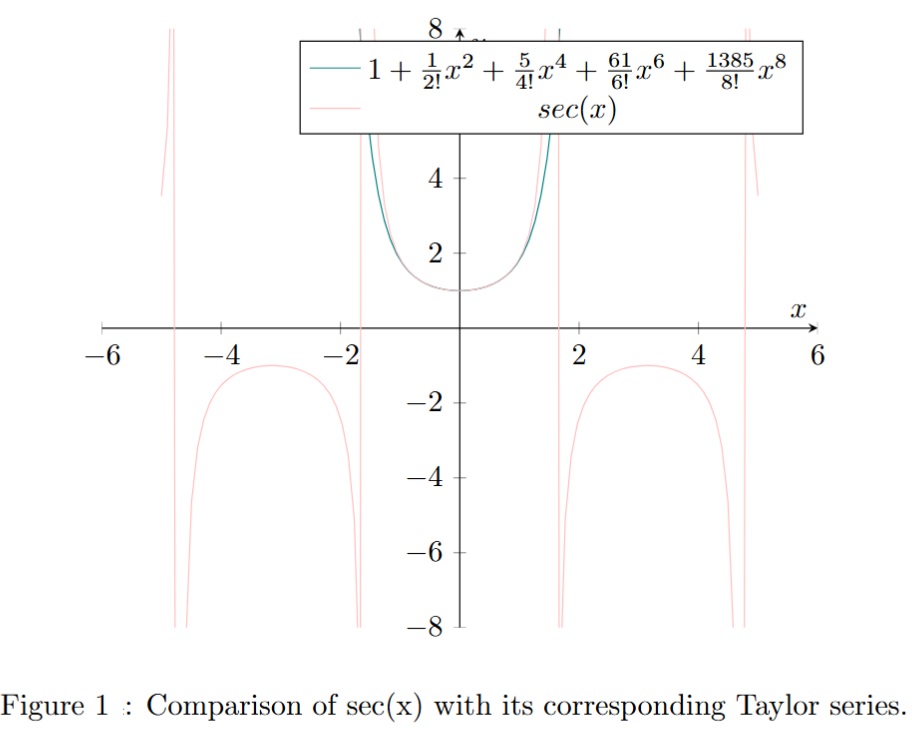
Therefore, the , and Padé approximants (see fig. 3, 4 and 5) of are equivalent to the first terms of its continued fraction as presented above.
The results above about suggest that a “Padé transformation” (i.e. converting a series into a rational function using the procedure described above) of a divergent Maclaurin and Taylor series is converging beyond the radius of convergence of the Maclaurin series.
This gives hope for the use of divergent series as often encountered in perturbation theory.
We would like to calculate the of . First, we would like to calculate . We, therefore, consider the Maclaurin series of up to 1 + 1 = 2 degrees:
Keeping only degrees up to 2:
This implies:
Solving the set of equations above gives:
We observe that is equivalent to the first term of the continued fraction of as presented above:
Figure 6 shows 16 Padé Approximants for . Figure 7 shows , , , and .
































 function. The approximation was not very impressive compared to the Maclaurin series of
function. The approximation was not very impressive compared to the Maclaurin series of  since the latter converges for all
since the latter converges for all  . In this post we will have a look at the Padé approximants and Maclaurin series of
. In this post we will have a look at the Padé approximants and Maclaurin series of  .
.

 are so-called Euler numbers:
are so-called Euler numbers:
 approximant of
approximant of 
 and
and 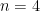 we have:
we have:





 coefficients:
coefficients:





 approximants in a table like this:
approximants in a table like this: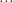
















 . Solving systems presented in the previous posts, leads to the following table:
. Solving systems presented in the previous posts, leads to the following table:




























 evaluated at x = 1, using the exact value
evaluated at x = 1, using the exact value  are shown in the table below:
are shown in the table below:











 , approaching it from both sides. In contrast, the Taylor approximations converge monotonically from below.
, approaching it from both sides. In contrast, the Taylor approximations converge monotonically from below.
 are the coefficients of the Taylor series. The matrix above is called a “Hankel matrix”. A ‘Hankel Matrix’ is a symmetric square matrix in which each ascending skew-diagonal from left to right is constant. For Example a Hankel matrix of size 5 can be written like this:
are the coefficients of the Taylor series. The matrix above is called a “Hankel matrix”. A ‘Hankel Matrix’ is a symmetric square matrix in which each ascending skew-diagonal from left to right is constant. For Example a Hankel matrix of size 5 can be written like this:
 :
:

 etc. This notation of the terms of the determinants implies that:
etc. This notation of the terms of the determinants implies that:





 is a even function of class
is a even function of class  , we see that odd coefficients
, we see that odd coefficients  . In this case, every second term of in the Hankel matrix is zero. If
. In this case, every second term of in the Hankel matrix is zero. If  and
and  are odd then the Hankel determinant is zero:
are odd then the Hankel determinant is zero:  of the Hankel determinant is
of the Hankel determinant is  . As stated before, this term is zero for an even function if
. As stated before, this term is zero for an even function if  is odd. Now, if
is odd. Now, if  is even and
is even and  is even. It follows that, in the case of an even function, the Hankel determinant is of the form:
is even. It follows that, in the case of an even function, the Hankel determinant is of the form:

 of cosine:
of cosine:
 and
and 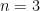 (
(

 up to terms
up to terms  :
:
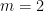 and
and 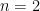 , the Hankel determinant (see previous
, the Hankel determinant (see previous 


 and
and  we have to solve:
we have to solve:
 and
and  .
. being set to one):
being set to one):

 ,
,  and
and  . The
. The 


 . To convert this (potentially not converging) series to its corresponding Padé approximant we write (as described in the previous post):
. To convert this (potentially not converging) series to its corresponding Padé approximant we write (as described in the previous post):
 :
:








 for
for  . We can split this system of equations in two parts and get rid of the x-terms. One part containing the
. We can split this system of equations in two parts and get rid of the x-terms. One part containing the 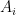 coefficients (up to i+j = m) and the part without
coefficients (up to i+j = m) and the part without 





 without loss of generality the second system of equations becomes:
without loss of generality the second system of equations becomes:







 . The resolution of the second system gives the values of the
. The resolution of the second system gives the values of the  coefficients which are injected into the first system to obtain the
coefficients which are injected into the first system to obtain the 

 is:
is: