We have seen that Padé approximants offer a more efficient and flexible method for approximating functions than the Taylor expansion. They have been used in many areas of mathematics and physics.
We would like to find a more convenient way to calculate the Padé coefficients of any Taylor or Maclaurin series.
In the following post, we admit the existence of Padé approximants 

If we want to solve a very hard or even impossible-to-solve-exactly problem using perturbation theory we will end up with a power series like 

From a purely algorithmic point of view and in order to calculate the Padé coefficients we drop 


Comparing each term of the geometric series on the right and the left of this equation (Uniqueness of power series coeffficients) we obtain the following set of equations:







Using 

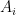




The second system of equations:


Setting 



Changing the order of the coefficients gives:



We can write both systems using matrix notation:


Practically, we start calculations where 


Is not null. i.e.:

the Padé approximant will be unique. The calculations for the Padé approximant coefficients yield a unique solution for any Taylor or Maclaurin series, provided the Hankel determinant is not null, excluding cases of degeneracy due to specific coefficient values.

Leave a comment