The previous post illustrates the general strategy: the admissible scalings are obtained from the intersections of the affine exponent functions. In this post, we explain why this construction works. Consider a perturbed polynomial of the form
After the scaling
each monomial becomes
Thus every monomial defines an affine function
The exponents of  are therefore completely described by the family of affine functions
are therefore completely described by the family of affine functions
The key observation is that, as  , the smallest exponent dominates all the others. Indeed, if
, the smallest exponent dominates all the others. Indeed, if
then
Consequently, for a fixed value of  , only the monomials whose exponent is minimal contribute to the dominant part of the polynomial.
, only the monomials whose exponent is minimal contribute to the dominant part of the polynomial.
Now suppose that one affine function lies strictly below all the others. Then a single monomial dominates, and the limit polynomial consists of only one term.
The interesting situation occurs when two affine functions intersect and their common value is the minimum among all the exponents. At such a point,
so two monomials have exactly the same asymptotic order. After normalization, both survive in the limit polynomial, producing a non-trivial dominant part.
Not every intersection is relevant. Two affine functions may intersect while another affine function remains strictly below them. In that case, the common exponent is not minimal, and the corresponding scaling does not contribute to the dominant polynomial.
Therefore, the admissible scalings are obtained precisely from the intersection points where the common exponent is minimal.
Geometrically, this means that the admissible scalings correspond to the corners of the lower envelope of the affine functions (see previous post). This simple geometric picture explains why the graph of the exponents completely determines the regularization process.























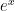


 , we associate it with the point
, we associate it with the point
 plane. The Newton polygon is defined as the lower convex hull of these points. Its edges contain exactly the information needed to determine the admissible scalings. Indeed, if an edge joins the points
plane. The Newton polygon is defined as the lower convex hull of these points. Its edges contain exactly the information needed to determine the admissible scalings. Indeed, if an edge joins the points









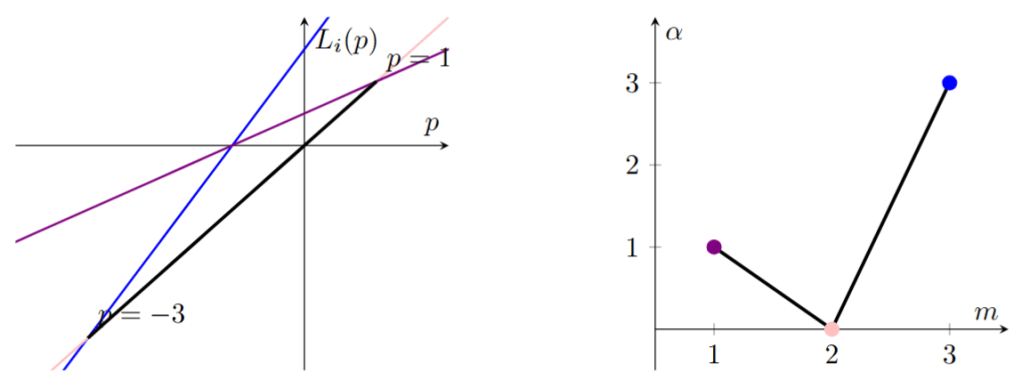










 ,
,  , and
, and  . Their intersection points determine the values of
. Their intersection points determine the values of 
 defined as follows:
defined as follows:




 . Therefore, we may write
. Therefore, we may write
 is the dominant part of
is the dominant part of  regularizes the perturbed polynomial
regularizes the perturbed polynomial  .
.
 is the intersection of the lines
is the intersection of the lines  , the minimum exponent is attained simultaneously by two monomials.
, the minimum exponent is attained simultaneously by two monomials.



 admit power-series expansions in
admit power-series expansions in  ‘s are rational numbers and
‘s are rational numbers and  ‘s,
‘s, 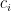 ‘s are constants.
‘s are constants.






 is a continuous function near zero. For convenience, we simply write
is a continuous function near zero. For convenience, we simply write  . If the theorem holds, the polynomial above becomes:
. If the theorem holds, the polynomial above becomes:

 and have:
and have:
 is a root of
is a root of 
 to determine the leading-order behavior:
to determine the leading-order behavior:

 to hold, the minimal value of the set
to hold, the minimal value of the set  must be exactly
must be exactly  , and this minimum must be shared by at least two distinct exponents. These identical minimal exponents define the dominant terms of
, and this minimum must be shared by at least two distinct exponents. These identical minimal exponents define the dominant terms of 
 may have fewer roots than the original polynomial. In this situation, some roots have escaped to a different scale and are therefore
may have fewer roots than the original polynomial. In this situation, some roots have escaped to a different scale and are therefore 
 , one obtains a new limiting polynomial in the variable
, one obtains a new limiting polynomial in the variable  . This reduced polynomial captures the asymptotic behavior of the roots on the corresponding scale and typically restores the correct number of roots.
. This reduced polynomial captures the asymptotic behavior of the roots on the corresponding scale and typically restores the correct number of roots.






 . The rescaling has therefore recovered the root that was hidden in the singular limit.
. The rescaling has therefore recovered the root that was hidden in the singular limit.

 we have:
we have:




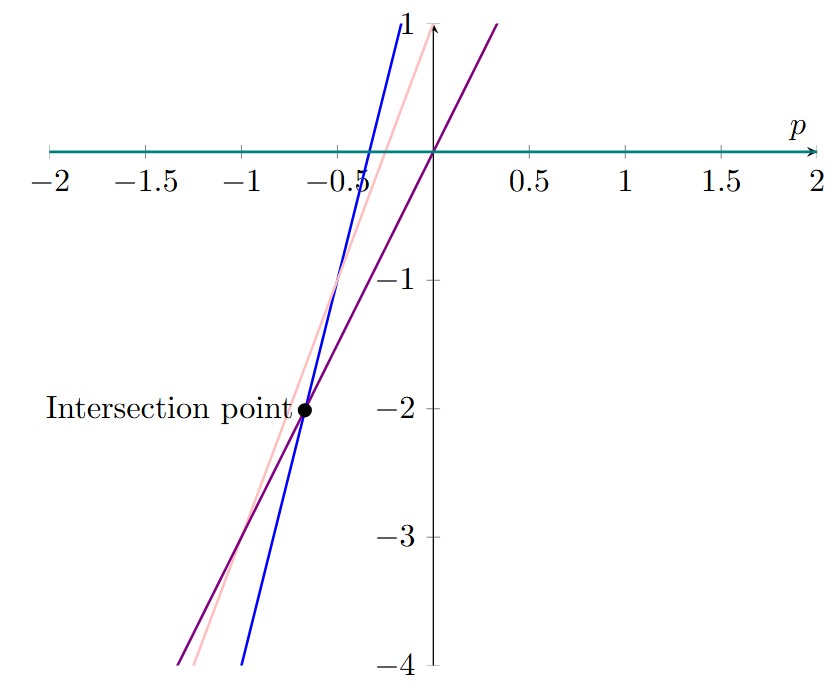
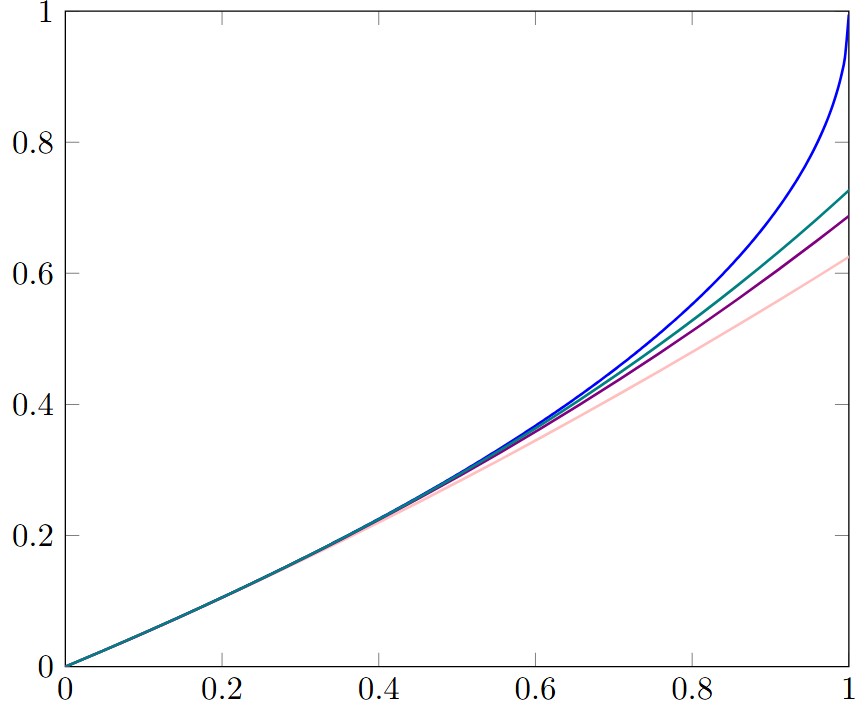
 ,
,  ) and plot them in a graph as a function of p (see figure below). If we think of the lines on the graph as delimiting a figure in the plane, we can select the vertex of this figure with the largest p value and the smallest f(p) value. In our case, the point corresponding to this criterion is the point of intersection of the lines
) and plot them in a graph as a function of p (see figure below). If we think of the lines on the graph as delimiting a figure in the plane, we can select the vertex of this figure with the largest p value and the smallest f(p) value. In our case, the point corresponding to this criterion is the point of intersection of the lines  and
and  . We thus obtain the point of intersection with coordinates (
. We thus obtain the point of intersection with coordinates ( ).
).
 and
and 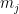 respectively.
respectively.








 (
( is always the answer to the unperturbed problem). We can use Python to expand the perturbative series and compute the coefficients (see code below). In this example we will calculate up to six coefficients.
is always the answer to the unperturbed problem). We can use Python to expand the perturbative series and compute the coefficients (see code below). In this example we will calculate up to six coefficients.






 is (setting
is (setting  ):
):




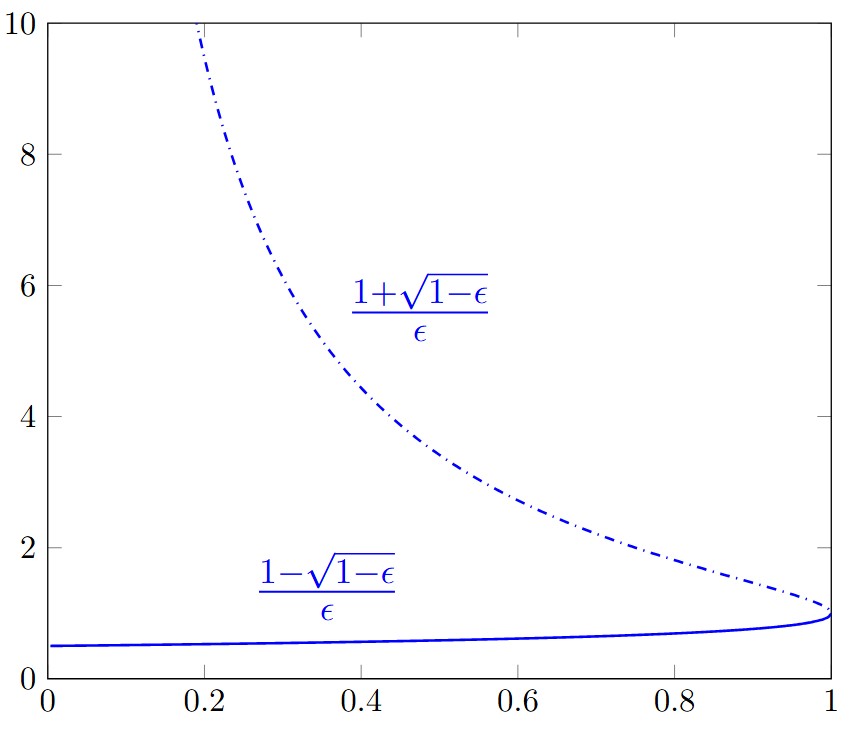
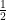 as
as  , the other goes to infinity. This is a manifestation of a singular behaviour. The problems above illustrate the importance of setting
, the other goes to infinity. This is a manifestation of a singular behaviour. The problems above illustrate the importance of setting  is
is  . We would like to calculate the corresponding perturbative series.
. We would like to calculate the corresponding perturbative series.



 ,
,  ,
, 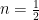 therefore:
therefore:








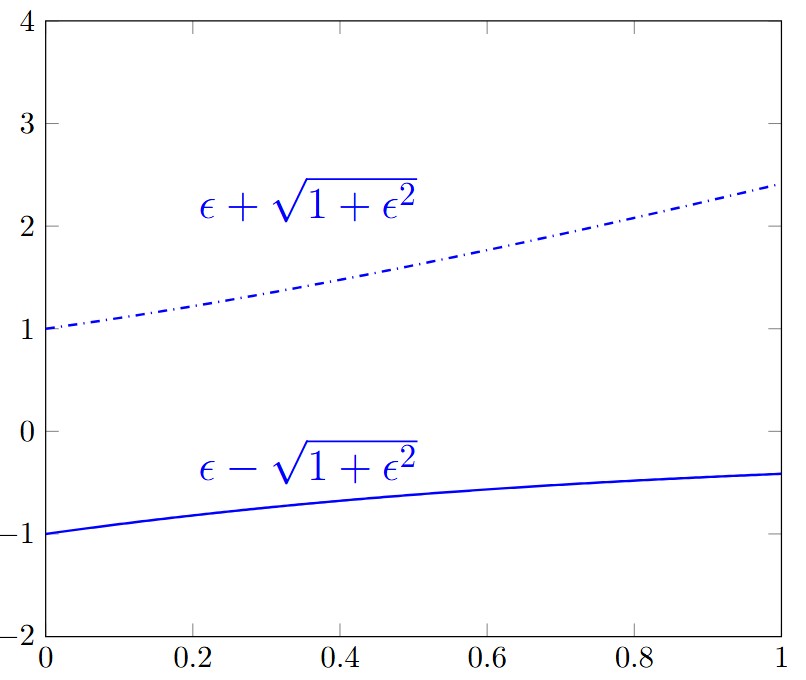
 using perturbation theory. For
using perturbation theory. For  the solutions are -1 and 1 and for
the solutions are -1 and 1 and for  the solutions are exactly
the solutions are exactly  and
and  .
.



 .
.